How to flatten an object in JavaScript

October 30, 2023
Flattening an object in JavaScript means transforming an object with nested properties into an object with only one level of depth, where each key represents a path to the original nested value. This process is helpful when you want to simplify data structures for easier processing or for sending to an API that expects flattened data.
Understanding object flattening
Object flattening requires recursion or iteration, handling each property differently based on whether it's a primitive value or a nested object. The challenge lies in ensuring that the keys of the flattened object accurately represent the hierarchy of the original object.
Writing a flatten function
To flatten an object, you'll need a function that can recursively traverse all properties and sub-properties of the object, keeping track of the property names to build the new keys for the flattened object.
Define the flatten function
Start with a function that accepts an object and an optional prefix for nested keys.
function flattenObject(obj, parentKey = '') { let flattened = {}; for (let key in obj) { if (obj.hasOwnProperty(key)) { const propName = parentKey ? `${parentKey}.${key}` : key; if (typeof obj[key] === 'object' && obj[key] !== null && !Array.isArray(obj[key])) { Object.assign(flattened, flattenObject(obj[key], propName)); } else { flattened[propName] = obj[key]; } } } return flattened; }
Handling edge cases
You might need to handle edge cases such as array properties, null values, or objects with circular references.
For arrays, decide whether to keep them intact or to further flatten their content.
For null values, the above code treats them as primitives. Circular references need to be detected and handled to avoid infinite recursion.
Flattening arrays
If you choose to flatten arrays, you could modify the recursive step to handle array elements as objects, potentially prefixing with their index.
// Modify this part of the function if (typeof obj[key] === 'object' && obj[key] !== null) { if (Array.isArray(obj[key])) { for (let i = 0; i < obj[key].length; i++) { Object.assign(flattened, flattenObject(obj[key][i], `${propName}[${i}]`)); } } else { Object.assign(flattened, flattenObject(obj[key], propName)); } } else { flattened[propName] = obj[key]; }
You could ship faster.
Imagine the time you'd save if you never had to build another internal tool, write a SQL report, or manage another admin panel again. Basedash is built by internal tool builders, for internal tool builders. Our mission is to change the way developers work, so you can focus on building your product.
Testing the function
To ensure the function works correctly, test it with various objects, including those with nested objects, arrays, nulls, and other edge cases.
Example usage
const nestedObject = { name: 'John Doe', address: { street: '123 Main St', city: 'Anytown', zip: '12345' }, hobbies: ['reading', 'gaming'] }; const flattened = flattenObject(nestedObject); console.log(flattened);
This should output an object where address.street is now address.street and hobbies[0] is hobbies[0] if you've chosen to flatten arrays as well.
Considerations for production code
Handling special object types
Date objects are not plain serializable objects and may need to be converted to strings or timestamps to be properly included in the flattened result.
Functions, if they are to be preserved, might need to be converted into strings using their toString() method, although this is often not useful for execution purposes.
Symbols are often used as unique keys and cannot be directly converted to strings.
To handle these special types, your flatten function may need to incorporate type checking and decide on a serialization strategy that suits your use case, such as ignoring functions and symbols or storing them in a way that can be re-interpreted later.
Circular reference checks
Circular references occur when an object references itself directly or through one of its child objects. This can cause infinite loops in a naive flatten implementation.
To safeguard against this, you could maintain a set or map of visited objects during the traversal process. Before processing an object property, check if the object has already been visited. If it has, you can either skip flattening that property or handle it in a manner that denotes a circular reference, such as assigning a special string or symbol to indicate the repetition.
Implementing this check will ensure that your flatten function is robust and can handle complex object graphs without falling into recursive traps.
Customization options for flattening
Different scenarios might require different flattening behaviors, especially when dealing with arrays and deciding whether to include or exclude certain properties.
For arrays, you might want to provide an option to keep them as-is, flatten them fully, or flatten them to a certain depth. For properties, an inclusion/exclusion list could be useful. Users of your flatten function could pass an options object that specifies the behavior for arrays and sets rules for property handling. This could be done using glob patterns, regular expressions, or callbacks that take a property key and return a boolean indicating whether to include it.
These customization options make the function more flexible and capable of handling a wide range of data shapes and requirements.
Further optimizations
Lastly, for performance-sensitive applications, test and optimize the function. Consider iterative approaches if the recursive calls become too costly for large or deeply nested objects. Profiling and benchmarking are key to ensuring the function performs well under expected data loads.
TOC
October 30, 2023
Flattening an object in JavaScript means transforming an object with nested properties into an object with only one level of depth, where each key represents a path to the original nested value. This process is helpful when you want to simplify data structures for easier processing or for sending to an API that expects flattened data.
Understanding object flattening
Object flattening requires recursion or iteration, handling each property differently based on whether it's a primitive value or a nested object. The challenge lies in ensuring that the keys of the flattened object accurately represent the hierarchy of the original object.
Writing a flatten function
To flatten an object, you'll need a function that can recursively traverse all properties and sub-properties of the object, keeping track of the property names to build the new keys for the flattened object.
Define the flatten function
Start with a function that accepts an object and an optional prefix for nested keys.
function flattenObject(obj, parentKey = '') { let flattened = {}; for (let key in obj) { if (obj.hasOwnProperty(key)) { const propName = parentKey ? `${parentKey}.${key}` : key; if (typeof obj[key] === 'object' && obj[key] !== null && !Array.isArray(obj[key])) { Object.assign(flattened, flattenObject(obj[key], propName)); } else { flattened[propName] = obj[key]; } } } return flattened; }
Handling edge cases
You might need to handle edge cases such as array properties, null values, or objects with circular references.
For arrays, decide whether to keep them intact or to further flatten their content.
For null values, the above code treats them as primitives. Circular references need to be detected and handled to avoid infinite recursion.
Flattening arrays
If you choose to flatten arrays, you could modify the recursive step to handle array elements as objects, potentially prefixing with their index.
// Modify this part of the function if (typeof obj[key] === 'object' && obj[key] !== null) { if (Array.isArray(obj[key])) { for (let i = 0; i < obj[key].length; i++) { Object.assign(flattened, flattenObject(obj[key][i], `${propName}[${i}]`)); } } else { Object.assign(flattened, flattenObject(obj[key], propName)); } } else { flattened[propName] = obj[key]; }
You could ship faster.
Imagine the time you'd save if you never had to build another internal tool, write a SQL report, or manage another admin panel again. Basedash is built by internal tool builders, for internal tool builders. Our mission is to change the way developers work, so you can focus on building your product.
Testing the function
To ensure the function works correctly, test it with various objects, including those with nested objects, arrays, nulls, and other edge cases.
Example usage
const nestedObject = { name: 'John Doe', address: { street: '123 Main St', city: 'Anytown', zip: '12345' }, hobbies: ['reading', 'gaming'] }; const flattened = flattenObject(nestedObject); console.log(flattened);
This should output an object where address.street is now address.street and hobbies[0] is hobbies[0] if you've chosen to flatten arrays as well.
Considerations for production code
Handling special object types
Date objects are not plain serializable objects and may need to be converted to strings or timestamps to be properly included in the flattened result.
Functions, if they are to be preserved, might need to be converted into strings using their toString() method, although this is often not useful for execution purposes.
Symbols are often used as unique keys and cannot be directly converted to strings.
To handle these special types, your flatten function may need to incorporate type checking and decide on a serialization strategy that suits your use case, such as ignoring functions and symbols or storing them in a way that can be re-interpreted later.
Circular reference checks
Circular references occur when an object references itself directly or through one of its child objects. This can cause infinite loops in a naive flatten implementation.
To safeguard against this, you could maintain a set or map of visited objects during the traversal process. Before processing an object property, check if the object has already been visited. If it has, you can either skip flattening that property or handle it in a manner that denotes a circular reference, such as assigning a special string or symbol to indicate the repetition.
Implementing this check will ensure that your flatten function is robust and can handle complex object graphs without falling into recursive traps.
Customization options for flattening
Different scenarios might require different flattening behaviors, especially when dealing with arrays and deciding whether to include or exclude certain properties.
For arrays, you might want to provide an option to keep them as-is, flatten them fully, or flatten them to a certain depth. For properties, an inclusion/exclusion list could be useful. Users of your flatten function could pass an options object that specifies the behavior for arrays and sets rules for property handling. This could be done using glob patterns, regular expressions, or callbacks that take a property key and return a boolean indicating whether to include it.
These customization options make the function more flexible and capable of handling a wide range of data shapes and requirements.
Further optimizations
Lastly, for performance-sensitive applications, test and optimize the function. Consider iterative approaches if the recursive calls become too costly for large or deeply nested objects. Profiling and benchmarking are key to ensuring the function performs well under expected data loads.
October 30, 2023
Flattening an object in JavaScript means transforming an object with nested properties into an object with only one level of depth, where each key represents a path to the original nested value. This process is helpful when you want to simplify data structures for easier processing or for sending to an API that expects flattened data.
Understanding object flattening
Object flattening requires recursion or iteration, handling each property differently based on whether it's a primitive value or a nested object. The challenge lies in ensuring that the keys of the flattened object accurately represent the hierarchy of the original object.
Writing a flatten function
To flatten an object, you'll need a function that can recursively traverse all properties and sub-properties of the object, keeping track of the property names to build the new keys for the flattened object.
Define the flatten function
Start with a function that accepts an object and an optional prefix for nested keys.
function flattenObject(obj, parentKey = '') { let flattened = {}; for (let key in obj) { if (obj.hasOwnProperty(key)) { const propName = parentKey ? `${parentKey}.${key}` : key; if (typeof obj[key] === 'object' && obj[key] !== null && !Array.isArray(obj[key])) { Object.assign(flattened, flattenObject(obj[key], propName)); } else { flattened[propName] = obj[key]; } } } return flattened; }
Handling edge cases
You might need to handle edge cases such as array properties, null values, or objects with circular references.
For arrays, decide whether to keep them intact or to further flatten their content.
For null values, the above code treats them as primitives. Circular references need to be detected and handled to avoid infinite recursion.
Flattening arrays
If you choose to flatten arrays, you could modify the recursive step to handle array elements as objects, potentially prefixing with their index.
// Modify this part of the function if (typeof obj[key] === 'object' && obj[key] !== null) { if (Array.isArray(obj[key])) { for (let i = 0; i < obj[key].length; i++) { Object.assign(flattened, flattenObject(obj[key][i], `${propName}[${i}]`)); } } else { Object.assign(flattened, flattenObject(obj[key], propName)); } } else { flattened[propName] = obj[key]; }
You could ship faster.
Imagine the time you'd save if you never had to build another internal tool, write a SQL report, or manage another admin panel again. Basedash is built by internal tool builders, for internal tool builders. Our mission is to change the way developers work, so you can focus on building your product.
Testing the function
To ensure the function works correctly, test it with various objects, including those with nested objects, arrays, nulls, and other edge cases.
Example usage
const nestedObject = { name: 'John Doe', address: { street: '123 Main St', city: 'Anytown', zip: '12345' }, hobbies: ['reading', 'gaming'] }; const flattened = flattenObject(nestedObject); console.log(flattened);
This should output an object where address.street is now address.street and hobbies[0] is hobbies[0] if you've chosen to flatten arrays as well.
Considerations for production code
Handling special object types
Date objects are not plain serializable objects and may need to be converted to strings or timestamps to be properly included in the flattened result.
Functions, if they are to be preserved, might need to be converted into strings using their toString() method, although this is often not useful for execution purposes.
Symbols are often used as unique keys and cannot be directly converted to strings.
To handle these special types, your flatten function may need to incorporate type checking and decide on a serialization strategy that suits your use case, such as ignoring functions and symbols or storing them in a way that can be re-interpreted later.
Circular reference checks
Circular references occur when an object references itself directly or through one of its child objects. This can cause infinite loops in a naive flatten implementation.
To safeguard against this, you could maintain a set or map of visited objects during the traversal process. Before processing an object property, check if the object has already been visited. If it has, you can either skip flattening that property or handle it in a manner that denotes a circular reference, such as assigning a special string or symbol to indicate the repetition.
Implementing this check will ensure that your flatten function is robust and can handle complex object graphs without falling into recursive traps.
Customization options for flattening
Different scenarios might require different flattening behaviors, especially when dealing with arrays and deciding whether to include or exclude certain properties.
For arrays, you might want to provide an option to keep them as-is, flatten them fully, or flatten them to a certain depth. For properties, an inclusion/exclusion list could be useful. Users of your flatten function could pass an options object that specifies the behavior for arrays and sets rules for property handling. This could be done using glob patterns, regular expressions, or callbacks that take a property key and return a boolean indicating whether to include it.
These customization options make the function more flexible and capable of handling a wide range of data shapes and requirements.
Further optimizations
Lastly, for performance-sensitive applications, test and optimize the function. Consider iterative approaches if the recursive calls become too costly for large or deeply nested objects. Profiling and benchmarking are key to ensuring the function performs well under expected data loads.
What is Basedash?
What is Basedash?
What is Basedash?
Ship faster, worry less with Basedash
Ship faster, worry less with Basedash
Ship faster, worry less with Basedash
You're busy enough with product work to be weighed down building, maintaining, scoping and developing internal apps and admin panels. Forget all of that, and give your team the admin panel that you don't have to build. Launch in less time than it takes to run a standup.
You're busy enough with product work to be weighed down building, maintaining, scoping and developing internal apps and admin panels. Forget all of that, and give your team the admin panel that you don't have to build. Launch in less time than it takes to run a standup.
You're busy enough with product work to be weighed down building, maintaining, scoping and developing internal apps and admin panels. Forget all of that, and give your team the admin panel that you don't have to build. Launch in less time than it takes to run a standup.
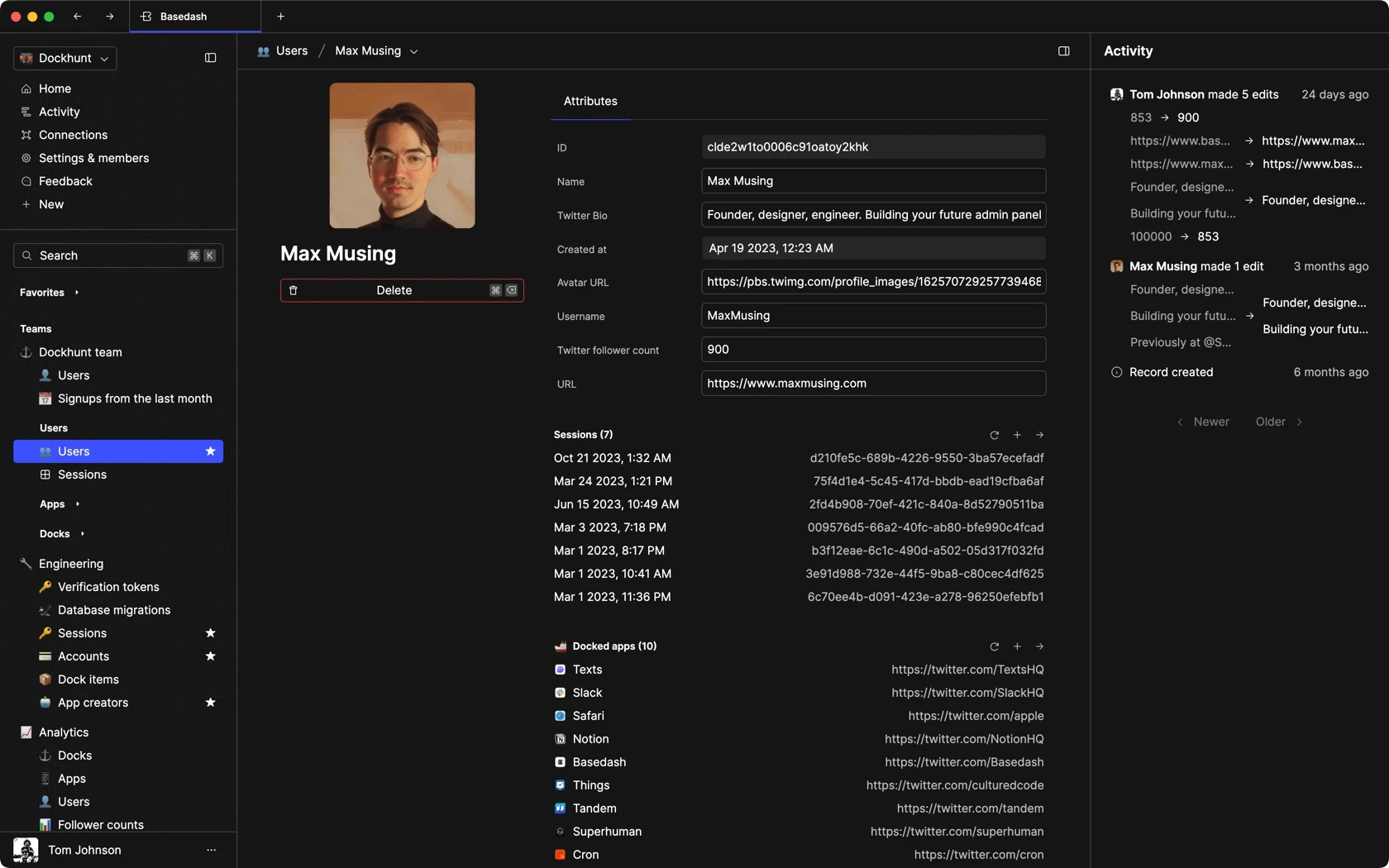
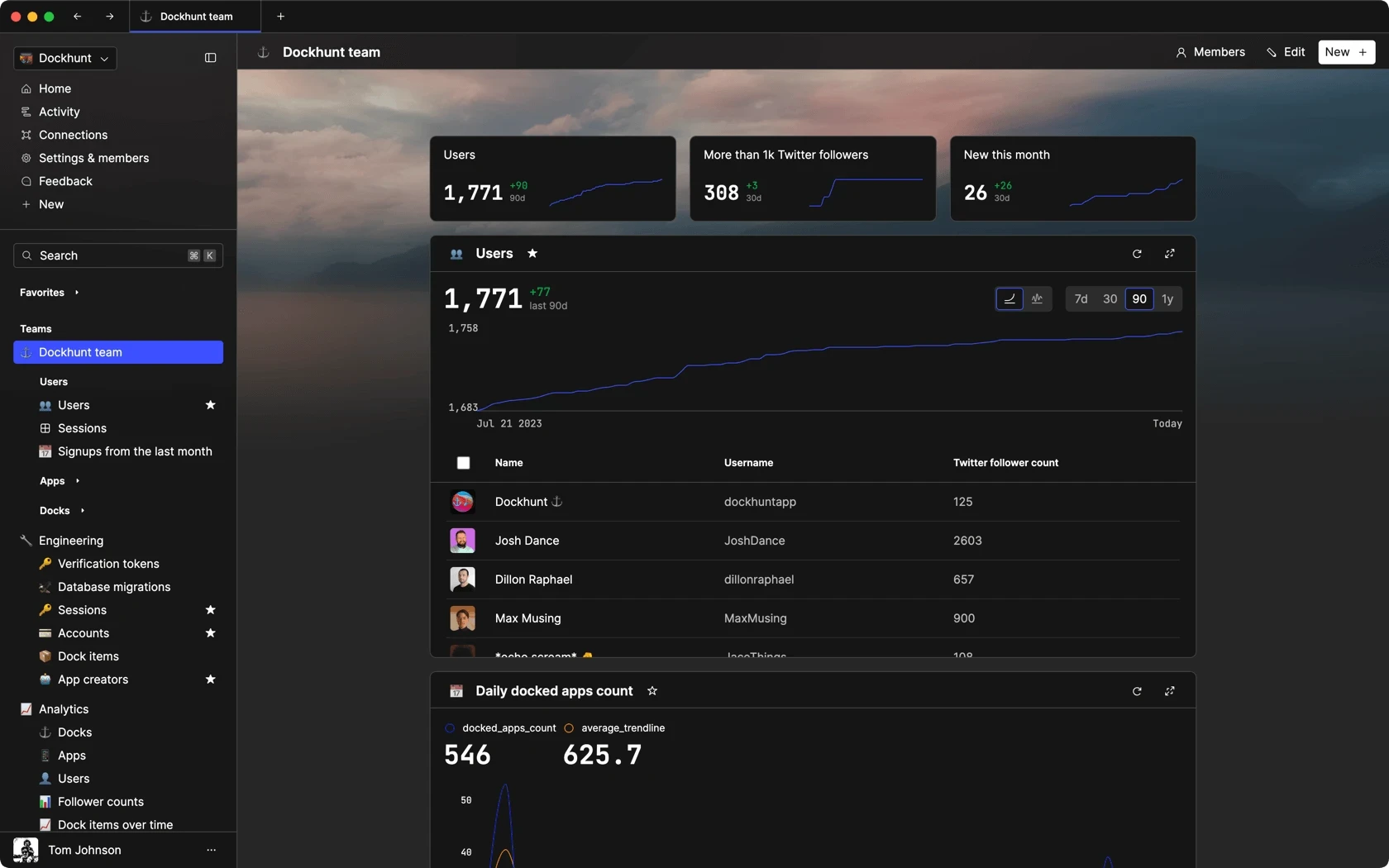
Dashboards and charts
Edit data, create records, oversee how your product is running without the need to build or manage custom software.
USER CRM
ADMIN PANEL
SQL COMPOSER WITH AI
Related posts
Related posts
Related posts

How to Remove Characters from a String in JavaScript
Jeremy Sarchet
How to Sort Strings in JavaScript
Max Musing
How to Remove Spaces from a String in JavaScript
Jeremy Sarchet

Detecting Prime Numbers in JavaScript
Robert Cooper

How to Parse Boolean Values in JavaScript
Max Musing
How to Remove a Substring from a String in JavaScript
Robert Cooper